
Snipaste的OCR文字识别功能潜力与应用场景 #
在数字化工作流中,信息捕获与转换的效率直接决定了生产力水平。截图软件早已超越简单的“屏幕拍照”范畴,进化成为集捕捉、编辑、管理于一体的综合效率平台。在众多功能中,光学字符识别(OCR)技术正成为区分基础工具与专业利器的关键特性。Snipaste,这款以极致体验著称的截图贴图软件,其内置的OCR功能虽不显山露水,却蕴藏着巨大的潜力,足以将静态图像中的文本信息转化为可编辑、可搜索、可再加工的数字化资产。本文旨在深度挖掘Snipaste OCR功能的完整能力边界,并提供一系列经过验证的高效应用场景与实操指南,帮助用户彻底释放这一“隐藏宝石”的能量。
一、Snipaste OCR功能核心技术解析 #
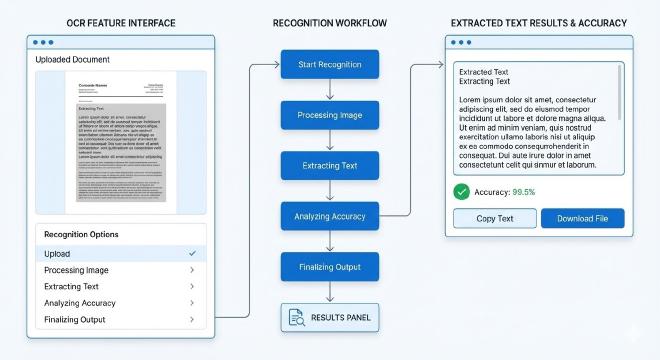
要充分利用一项功能,首先需理解其背后的工作机制与能力边界。Snipaste的OCR并非一个独立的应用程序,而是深度集成在其标注与编辑体系中的一个智能模块。
1.1 功能入口与激活方式 #
Snipaste的OCR功能并未在主界面上设置独立按钮,其激活方式体现了“工具服务于流程”的设计哲学:
- 主要路径:完成一次截图后,进入截图编辑工具栏。在工具栏中,找到并点击**文本识别(OCR)**图标(通常显示为“T”与扫描线结合的符号)。
- 快捷方式:部分版本支持在截图后使用预定义的快捷键(需在设置中查看或自定义)直接触发OCR识别,实现无缝操作。
- 识别范围:可对整个截图区域进行识别,也支持在截图后,使用矩形选择工具框选特定区域进行精准识别,这尤其适用于界面中文字密集或混合排版的场景。
1.2 技术特性与识别精度 #
Snipaste采用的OCR引擎兼顾了速度与准确率,其特性包括:
- 多语言支持:能够较好地识别中英文混合文本,对常见的简体中文、英文印刷体字体识别率较高。这对于处理技术文档、学术论文、国际化软件界面至关重要。
- 版面分析:具备基础的版面保持能力,能识别出文本的换行、段落分隔,甚至简单的多栏布局,使得识别结果更贴近原始排版逻辑,减少后期整理工作量。
- 抗干扰能力:对常见的屏幕文本显示有优化,如能一定程度抵抗亚像素渲染、字体抗锯齿带来的影响。但对于严重扭曲、艺术字体、极低分辨率或复杂背景图片上的文字,识别准确率会自然下降。
- 输出处理:识别完成后,文本内容会直接出现在一个可编辑的文本框内,用户可以立即进行校对、修改。同时,识别出的文本会自动复制到系统剪贴板,方便一键粘贴到任何其他应用程序(如Word、记事本、聊天窗口、代码编辑器)。
理解这些特性是制定有效使用策略的基础。它并非万能的通用OCR,但在其设计目标场景——从计算机屏幕、数字文档、清晰图像中提取规整文本——下表现卓越。
二、核心应用场景与实操指南 #
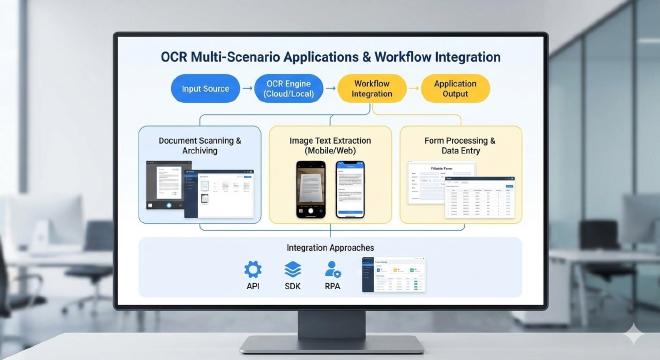
Snipaste OCR的价值在于其与截图工作流的无缝结合,创造了"所见即所得,所得即可用"的高效闭环。以下分场景详述其应用。
2.1 场景一:高效资料收集与文献整理 #
无论是学生进行学术研究,还是职场人士撰写报告,从不可复制的PDF、网页或图片中提取文字是高频需求。
实操步骤:
- 定位与截图:使用Snipaste(默认快捷键
F1)截取包含所需文本的PDF阅读器、网页或图片查看器区域。 - 触发OCR:在截图编辑界面,点击OCR按钮或使用快捷键。
- 校对与编辑:在弹出的文本框中快速核对识别结果,修正可能的错误字符。
- 即时输出:无需任何额外操作,文本已在剪贴板。直接切换到你的笔记软件(如Notion、OneNote)、文献管理工具(如Zotero)或Word文档,按
Ctrl+V粘贴即可。 - 结构化处理:对于多段文本,可以分次截图识别,或利用Snipaste的贴图对比功能,将不同来源的文本贴图并列悬浮,方便进行综合比对和摘录。关于贴图的高级用法,您可以参考我们之前的文章《Snipaste高阶贴图功能使用场景全解析》。
优势对比:传统方式需要打开专用OCR软件、导入图片、选择区域、输出文本、再复制粘贴,流程冗长。Snipaste将步骤压缩至两步:截图、识别(文本已就绪),效率提升显著。
2.2 场景二:编程开发与调试辅助 #
程序员经常需要从错误提示框、日志窗口、文档或他人代码截图(如在技术社区)中提取信息。
实操步骤:
- 捕获错误信息:当程序抛出错误对话框或控制台输出复杂堆栈信息时,快速截图。
- 识别关键代码与路径:对截图进行OCR,迅速将错误代码、文件路径从图像转为纯文本。
- 搜索与调试:将识别出的错误信息直接粘贴到搜索引擎或项目内部Wiki进行搜索,快速定位解决方案。或者将文件路径直接粘贴到终端或文件资源管理器进行导航。
- 代码片段复用:从技术博客、文档的代码示例截图中提取代码。识别后,粘贴到IDE中进行调试和运行。尽管识别代码时需注意缩进和特殊符号的准确性,但对于大多数清晰截图的简单代码块非常有效。这极大地补充了Snipaste如何辅助代码审查和编程调试工作中提到的纯视觉对比功能。
2.3 场景三:外语学习与翻译加速 #
阅读外文资料、学习软件或浏览海外网站时,快速翻译是刚需。
实操步骤:
- 截图外语文本:对不懂的外语句子或段落进行截图。
- OCR提取原文:使用Snipaste识别,获得原始外文文本。
- 调用翻译工具:将剪贴板中的文本直接粘贴到翻译软件(如DeepL、谷歌翻译浏览器插件、或有道词典)中,瞬间获得翻译结果。
- 制作学习卡片:将原文和翻译结果一起保存到Anki等记忆软件中,制作成复习卡片。
效率提升:避免了在键盘上艰难地输入不熟悉的外语字符,也避免了在翻译软件和原文窗口间来回切换的手动输入麻烦。
2.4 场景四:UI/UX设计与产品文案处理 #
设计师和产品经理需要从竞品截图、设计稿评审意见或各种素材中提取文案、颜色值等信息。
实操步骤:
- 提取竞品文案:分析竞品App或网站时,截图其界面文案,用OCR快速提取,用于文案风格分析或直接参考。
- 转换设计稿文本:有时收到的设计稿(如图片形式)中的文案需要提取为PRD文档。OCR可以快速完成这一转换。
- 结合取色器工作流:Snipaste强大的取色器功能可以获取界面颜色,而OCR可以获取界面文字,两者结合能对竞品界面进行快速、全面的信息采样。关于取色器的专业应用,可阅读《Snipaste取色器功能在UI设计中的妙用》。
2.5 场景五:行政办公与数据录入 #
处理扫描版合同、票据、表格图片,或从系统界面中提取数据录入Excel。
实操步骤:
- 处理扫描件:打开扫描的PDF或图片,对需要录入的文字区域截图。
- 批量识别:虽然Snipaste不支持批量图片OCR,但可以通过连续截图->识别->粘贴的循环,配合Excel或文本编辑器的快速编辑,高效处理多页文档。
- 抓取系统数据:从无法直接导出的老旧系统或特定软件界面中,截图表格或列表,OCR识别后,利用文本编辑器或Excel的“分列”功能,将数据结构化。
注意事项:对于印刷体表格,OCR能识别出文字,但无法自动恢复表格结构,需人工在Excel中调整。
三、提升OCR识别成功率的进阶技巧 #
即使是最好的OCR工具,面对复杂场景也需要一些技巧来优化。
3.1 预处理截图图像 #
- 确保清晰度:截图前,确保屏幕分辨率足够,文字显示清晰。可暂时调高显示器缩放比例。
- 简化背景:如果文字背景复杂,可先尝试调整原窗口主题或使用阅读模式,使文字对比度更高。
- 精准框选:识别前,在截图编辑器中用矩形工具精确框选文字区域,排除无关图像元素的干扰。
3.2 识别后的高效校对策略 #
- 利用上下文:对于不确定的识别字符(如“0”和“O”,“1”和“l”),结合上下文语义判断。
- 分段识别:对于大段文本,如果整体识别有个别区域错误率高,可针对该小区域单独截图再识别一次。
- 与历史记录结合:Snipaste的剪贴板历史功能可以保存最近识别出的文本,方便回溯和复用。具体管理方法可参见《Snipaste历史记录与剪贴板管理功能详解》。
3.3 与其他工具链集成 #
- 文本编辑器宏:将识别出的文本粘贴到支持宏的编辑器(如VS Code, Sublime Text),录制或编写简单的宏命令,自动完成格式清理(如去除多余空格、规范化换行)。
- 自动化脚本:通过AutoHotkey或系统自动化工具,将Snipaste截图->OCR->粘贴的流程编成一个快捷键,实现一键完成从图像到指定位置文本的转换。
四、局限性与替代方案探讨 #
客观认识局限,有助于在正确场景选择最佳工具。
4.1 Snipaste OCR的当前局限 #
- 批量处理:不支持一次性对多张图片或一个文件夹内的图片进行批量OCR处理。
- 复杂格式:对于包含复杂表格、流程图、数学公式、手写体的图片,识别能力有限或无法保持原结构。
- 离线与在线:Snipaste的OCR引擎通常是离线工作的,这保证了速度和隐私,但也意味着其模型更新可能不如某些云端OCR服务及时,对最新、最特殊字体的适应性可能稍弱。
4.2 何时需要寻求替代方案 #
- 专业文档数字化:需要处理大量扫描版书籍、档案,且要求保留精确版式和复杂格式时,应考虑ABBYY FineReader、Adobe Acrobat Pro等专业OCR软件。
- 手写体识别:需识别手写笔记或表格,应使用OneNote、Google Keep或专门的手写OCR应用。
- 云端协作与多格式:需要识别多国语言、并直接集成到云文档(如Google Docs)或翻译流程中,可选用在线OCR服务或内置强大OCR的笔记应用。
Snipaste OCR的核心优势在于其情境化、即时性。它是你当前屏幕工作流的自然延伸,解决的是“立刻、马上需要这段文字”的痛点,而非大规模的文档数字化项目。
五、未来展望与功能期待 #
随着AI技术的进步,OCR的潜力将进一步放大。我们对Snipaste未来OCR功能的演进抱有合理期待:
- 精准表格识别:能够将截图中的表格识别并直接输出为CSV或Excel可接受的格式。
- 代码识别增强:针对程序员群体,优化对等宽字体、代码缩进、特殊符号的识别,甚至能识别出语法高亮。
- 智能语义块分割:不仅能识别文字,还能判断标题、正文、列表、引用等语义块,输出带简单标记的结构化文本。
- 与贴图深度结合:识别出的文本可以直接生成一张干净、可调整样式的文本贴图,用于演示或临时备忘。
常见问题解答 (FAQ) #
Q1: Snipaste的OCR功能是免费的吗? A1: 是的,Snipaste的基础版本(包括OCR功能)对个人用户完全免费。其企业版可能包含额外的管理功能和支持,但核心OCR能力在免费版中即可完整使用。
Q2: 识别出的文本出现乱码或错误很多怎么办? A2: 首先检查截图源的文字是否清晰。尝试缩小识别区域,仅框选最清晰的部分。如果问题持续,可能是字体特殊或语言不支持。可以尝试调整原显示窗口的缩放比例或字体大小后重新截图。对于复杂情况,考虑使用更专业的OCR工具作为补充。
Q3: Snipaste OCR支持哪些语言?识别速度如何? A3: 主要支持简体中文和英文,对中英混合文本处理良好。识别速度极快,通常在1-3秒内完成,几乎感觉不到等待,这得益于其轻量化的离线引擎设计。
Q4: 能否将识别后的文本直接保存为文件? A4: Snipaste本身不提供直接保存为文本文件的功能。但识别后文本已复制到剪贴板,您可以立即打开记事本、文本编辑器或Word,粘贴后保存。这实际上提供了最大的灵活性,您可以保存为任何想要的格式。
Q5: 在识别代码时,如何保证缩进格式不丢失? A5: Snipaste OCR会尽力保持原始的换行和空格。为了最大程度保留代码缩进,请确保截图时使用等宽字体(如Consolas, Monaco),并且截图区域足够宽以包含所有行首空格。识别后粘贴到支持空白字符显示的编辑器(如VS Code,需开启“渲染空白字符”选项)中进行最终校对和调整。
结语 #
Snipaste的OCR功能,就像这把软件瑞士军刀中一把锋利而精准的锉刀。它没有独立成器的庞杂,却在你最需要将视觉信息转化为文本资产的瞬间,提供了一击即中的解决方案。通过本文揭示的从核心技术解析到跨领域应用场景,再到提升识别率的实操技巧,我们希望您能重新审视并深度整合这一功能到您的日常数字工作流中。
真正的效率提升,往往来自于对现有工具潜能的充分挖掘,而非不断追逐新软件。Snipaste OCR的价值,正在于它无缝嵌入了那个您已经无比熟悉的截图-贴图流程,无声地化解了从“看到”到“用到”之间的最后一厘米障碍。开始有意识地使用它吧,您会发现,处理屏幕上的文字信息,从未如此直接和流畅。
本文由Snipaste官网提供,欢迎浏览Snipaste下载网站了解更多资讯。